Demystifying Neural Networks: How Do They Really Work?
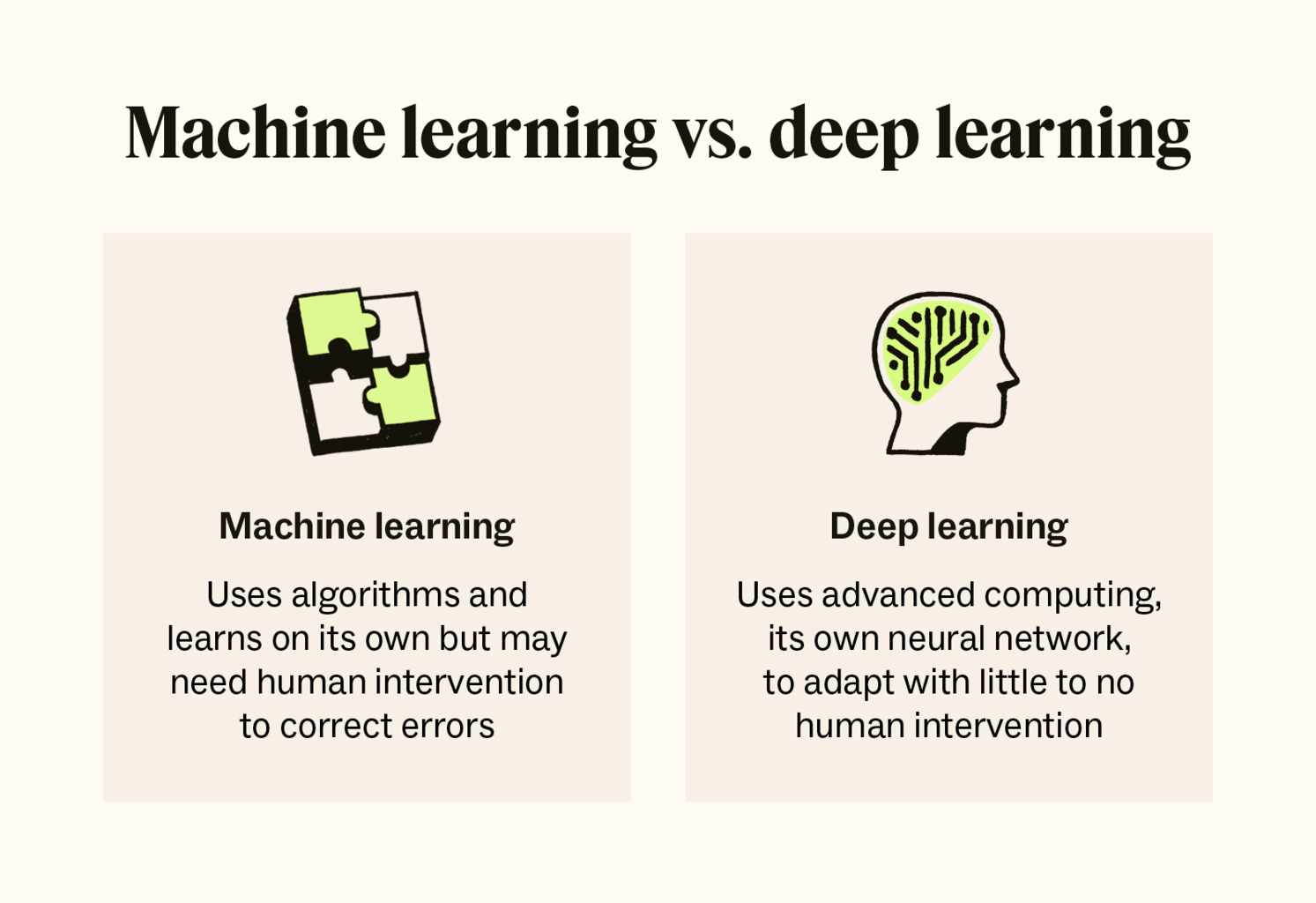
Neural networks are a subset of machine learning models inspired by the human brain. They consist of interconnected layers of nodes, or neurons, that process input data and learn to make predictions or classifications. Each neuron applies a mathematical function to the input, adjusting the connections' weights through a process called backpropagation. This iterative learning process involves feeding the network data, calculating the error in its predictions, and then updating the weights to minimize this error. As the network processes more data, it captures intricate patterns, allowing it to improve its performance over time.
To simplify, think of a neural network as a complex web where information travels from the input layer, through multiple hidden layers, to the output layer. Each layer abstracts the data further, extracting features that are increasingly sophisticated. For instance, in image recognition, the early layers might identify edges and textures, while deeper layers recognize shapes and objects. This hierarchical approach enables neural networks to effectively tackle tasks ranging from image and speech recognition to natural language processing. By demystifying these fundamental concepts, we gain a clearer understanding of how these powerful tools operate and their potential applications in various fields.
The Secrets Behind Machine Learning Algorithms: Explained!
Machine learning algorithms are at the heart of many advanced technologies today, enabling systems to learn from data and improve their performance over time. At its core, a machine learning algorithm processes input data, identifying patterns and making predictions based on that information. The most common types of algorithms include supervised, unsupervised, and reinforcement learning. Each type serves a unique purpose, tackling different challenges in data analysis. For instance, supervised learning algorithms like linear regression and decision trees are used for tasks where labeled data is available, while unsupervised learning techniques such as k-means clustering are utilized when the data lacks labels, helping discover hidden structures within the dataset.
One of the secrets behind the success of machine learning algorithms lies in their ability to continually adjust and optimize their parameters. This is achieved through methods like gradient descent, which minimizes the error in predictions by iteratively updating the algorithm's weights. Furthermore, the choice of features plays a crucial role in the performance of these algorithms. Techniques such as feature selection and feature engineering are employed to select the most relevant features and transform the raw data into a usable format, ultimately enhancing the model's accuracy. As technology advances, understanding these underlying principles of machine learning becomes essential for anyone looking to harness its power effectively.
Is AI Just a Fancy Term for Machine Learning?
In the realm of technology, the terms AI (Artificial Intelligence) and Machine Learning are often used interchangeably, leading to widespread confusion. While both concepts are interconnected, they are not the same. AI encompasses a broader spectrum, referring to systems designed to mimic human cognitive functions, such as understanding language or recognizing patterns. In contrast, Machine Learning is a subset of AI, focusing on the development of algorithms that enable computers to learn from and make predictions based on data. This relationship can be visualized as a hierarchy where Machine Learning is a crucial building block within the vast landscape of AI.
To better understand this distinction, consider the following points:
- Scope: AI includes various technologies such as robotics and natural language processing, while Machine Learning specifically deals with data-driven learning.
- Capabilities: AI aims to replicate human-like decision-making abilities, whereas Machine Learning focuses on improving performance through exposure to more data.